


前言|我們為什麼重新思考「決策」這件事?
上週我們分享了一篇文章,談的是「如何用 AI 幫助製造業轉型?」(👉 還沒看的可以點這裡)。當時我們談了很多關於自動化、AI Agent、MOM 架構等技術應用,文章發佈後,我們也反思了一個問題:
當我們說「AI 協助決策」,我們到底在描述什麼樣的「決策」?
過去,特別是製造業現場,決策常仰賴管理者的隱性經驗與直覺。但當 AI 進入企業流程,決策不再只是個人判斷,而是需要被拆解、被理解、被優化的過程。
帶著這樣的問題,我們讀了《Third Millennium Thinking: Creating Sense in a World of Nonsense》(中文版《三禧思維:亂世解決問題、活得更好的科學思考工具!》),意外地打開了更深一層的思考視角。這不是一本教你做選擇的書,而是一本幫助我們看懂「決策是如何形成」的工具書。它將決策分為三個核心維度,讓我們意識到:AI 的價值,不只在於資料處理,而是能否在這三個基礎上成為使用者的輔助。
接下來,我們將從這三個維度出發,探討如何避開決策陷阱,並分享鼎華的 APS 系統如何與決策對話,協助企業走向更有依據的智能決策。
摘要
這篇文章主要與你探討何謂「真正的決策」,從《三禧思維》這本書的角度,我們了解決策不只是資料分析的結果,而是一套兼顧資訊可信度、價值觀納入與決策程序正當性的思考過程——這正是書中提出的「決策三角」所揭示的核心。當這三角失衡,企業決策容易走向失真與反效果。而鼎華的 APS 系統,正是扮演連接資料與決策的智慧引擎,協助企業在複雜環境中建立穩定、可推論、可選擇的行動模型,走向真正有品質的 AI 智能決策。
目錄
一. 什麼是良好的決策?
在《Third Millennium Thinking》中,作者 Saul Perlmutter, John Campbell, Robert MacCoun 提出一個概念叫做「決策三角(The Decision Triangle)」,指出所有良好決策的背後,都必須同時滿足三項條件,分別為資訊來源的可靠性(Epistemic Validity)、價值觀的正當納入(Normative Integration)和決策權的正當性(Procedural Justice),由這三者所構成的「穩定結構」,一旦任一邊失衡做出的決策就容易變得偏頗、失真、甚至導致反效果。
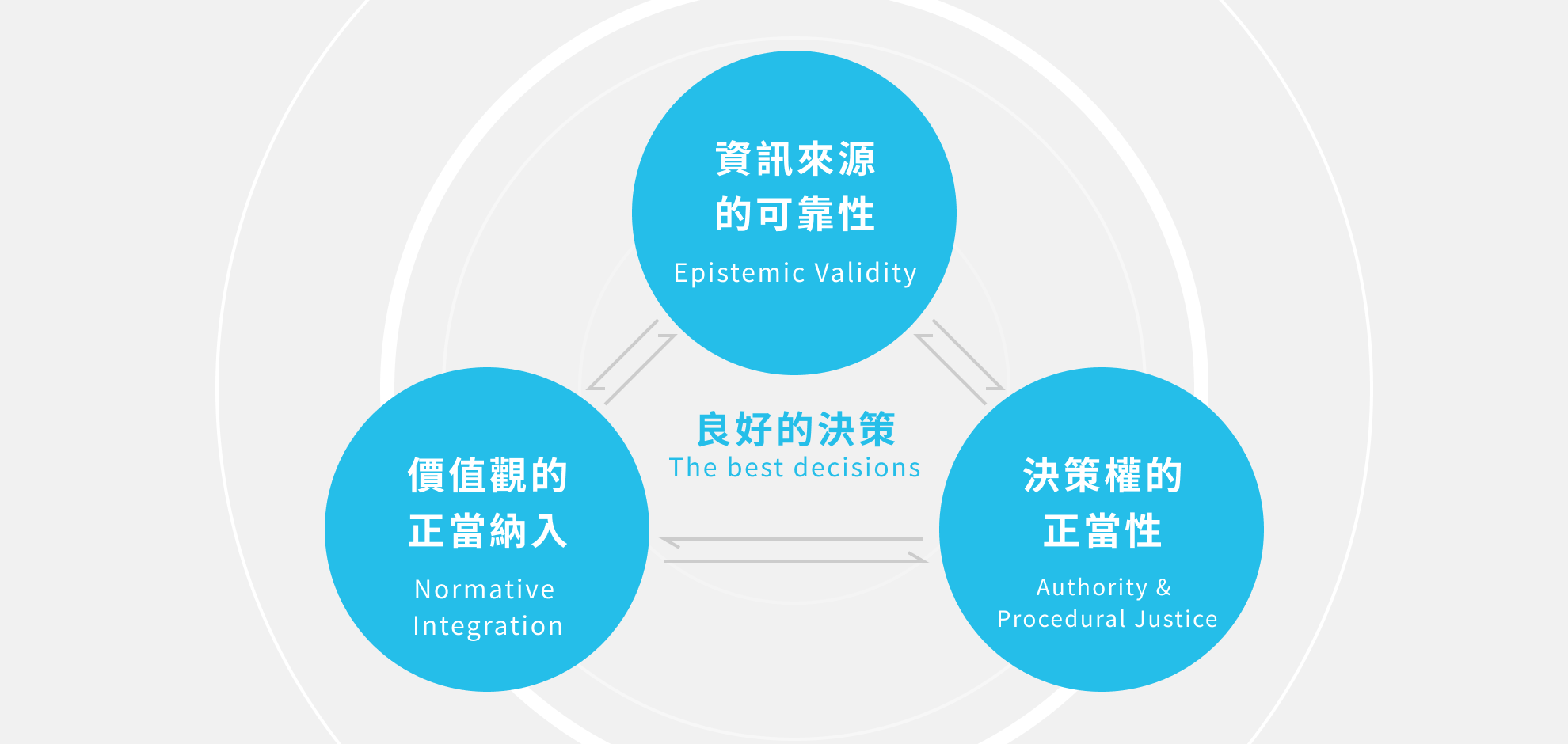
這三個條件聽起來很抽象,但一旦放進製造業情境中,你會發現:這正是我們每天在工廠裡、在系統裡、在排程會議中不斷碰到的真實問題。
-
資訊來源的可靠性(Epistemic Validity)
你給 AI 的世界,是清晰還是扭曲的,將決定著我們決策的依據是否真實、完整、可靠?
《Third Millennium Thinking》書中指出,許多錯誤決策的根源,其實不是邏輯推錯了,而是「資料源頭就不對」。就像輸入一張模糊地圖,你當然無法走到正確的目的地。這對我們來說,完全說中了導入智慧工廠時的痛點。
舉例來說,在製造業場域,我們最常遇到的情境:
- 機台數據來自不同廠牌,格式與頻率無法對齊
- 良率與報廢紀錄靠人工補填,無法驗證正確性
- 系統分散,各自為政,資料存在但彼此不說話
- 沒有標準欄位、沒有時間戳記、沒有資料血緣(Data Lineage)
這些問題,看似有資料,實則不可靠,因為 AI 無法「自動判斷」和「修正」。我們的理解是:「再強大的推理模型,也無法從錯誤的前提推導出正確的結論。」
這正是我們在建構 APS 系統時特別重視的:不只是把資料接進來,更要確保資料的來源、結構與關聯性是可以信任的。
鼎華的 APS 系統,透過與 MES、QMS 等系統深度整合,確保每一筆資料都有上下文、有時間序、有標準格式。當我們讀取機台停機紀錄時,不只知道「停了多久」,還能同步取得當下負責人員、加工產品、生產批次與品質異常紀錄。這樣的資料,才是 AI 真正能「理解工廠現場」的基礎。
換句話說,我們做的不是讓 AI 更會算,而是讓它知道它在算什麼。
當 AI 有了正確的世界觀,它的建議才有可能可靠;而這個世界觀,就是由你給它的資料建構出來的。
-
價值觀的正當納入(Normative Integration)
第二個決策基礎要素是「Normative Integration」,中文譯作「價值觀的正當納入」。這個概念的重點在於:光有事實還不夠,決策還需要回應價值層面的選擇。
意思是,數據能告訴我們發生了什麼,但它沒辦法告訴我們應該怎麼選。舉例來說,APS 系統可能可以清楚告訴你哪條產線的效率最高、哪批原料使用率最理想,但當你必須在「最低成本」與「最穩定交期」之間做選擇時,AI 本身無法決定你的優先順序。這就是價值介入的時刻。
我們每天面對的排程、派工、訂單管理,其實都隱含許多價值判斷,例如:
- 要不要為 VIP 客戶插單?影響其他訂單是否可接受?
- 是否接受週末加班趕工?還是堅持工作時數上限?
- 優先支持自製零件還是外包加工?怎麼衡量內外部風險?
這些問題都不是「算出來的」,而是「談出來的」——必須透過多角色協商、條件權重調整、運營目標校準或是經驗中的道德直覺與實務考量,才能找出對企業當下最合適的答案。
這也是鼎華在設計 APS 系統時,強調「排程的彈性邏輯設定」的原因之一。我們讓使用者可以設定權重優先順序(交期、產能、換線、庫存等),讓系統能夠根據不同場景的價值偏好給出不同排程建議,而不是一套固定邏輯套到底。
更進一步,我們也將「排程假設條件」可視化,讓使用者不只是看到結果,而是理解「這個決策是基於什麼價值判斷」,並在有需要時,快速調整策略方向。
隱性經驗是一種「非語言的價值納入機制」,AI 將它顯性化並分析,幫助你在價值選擇上定義。
我們相信,真正成熟的智慧決策,是能讓系統理解你的偏好,同時也讓人理解系統背後的邏輯,而不是被演算法綁架。
-
決策權的正當性(Procedural Justice)
第三個關鍵要素「Procedural Justice」,意即決策過程本身是否具備正當性與可被接受性。也就是說,決策不只是看「結果對不對」,更要看「誰做的、怎麼做的、能不能被理解與支持」,因為再好的建議,如果沒人接受,也只是空談。
你是否也遇到過這樣的情況?
- 系統排出了最佳化的排程,但現場主管不願配合調整
- 決策數據老闆看起來沒問題,但基層人員覺得「根本不符合現場實情」
- 系統改版後決策邏輯改變,卻沒通知生產人員,造成現場混亂甚至抗拒
這些狀況不是技術問題,而是「決策過程的正當性出問題」──人不清楚為什麼要這樣排、誰決定的、憑什麼這樣改變流程。
鼎華在設計 APS 系統時,始終強調「決策是協作的過程,不是單點的命令」。我們的系統不只要讓 AI 給出建議,更要讓使用者理解建議從哪裡來、怎麼來的、可不可以調整,並且保留「人」參與與覆核的空間。
為此,我們設計了以下幾個關鍵機制:
- 決策過程可視化:每一筆派工建議、換線推薦,皆標註其依據條件與目標優先序,讓使用者能「看得懂邏輯」。
- 排程版本記錄與追蹤:使用者可回溯不同版本的變更歷程,確保所有變動皆有紀錄、有討論依據。
- 協作權限與審核流程:針對高風險調整(如急單插單、優先權變更),可透過審批流程與通知機制,多角色共同確認,避免「黑箱式 AI 決定」。
這樣的設計,是為了讓決策的過程具備「透明度」與「參與感」,讓 AI 的建議不祇是空談,而是被團隊接受與執行。否則,即使 AI 算得再準,沒有「共識」與「信任」,也只是紙上談兵。
二. 當決策三角一失衡,就會引發這三種錯誤
我們知道良好的決策就像一座穩固的三角架,需要資訊可靠性、價值觀納入、與決策程序的正當性三者同時支撐。同樣的,當這三個面向出現偏失、失衡或缺漏時,就可能導致三種常見但常被忽視的錯誤決策模式。
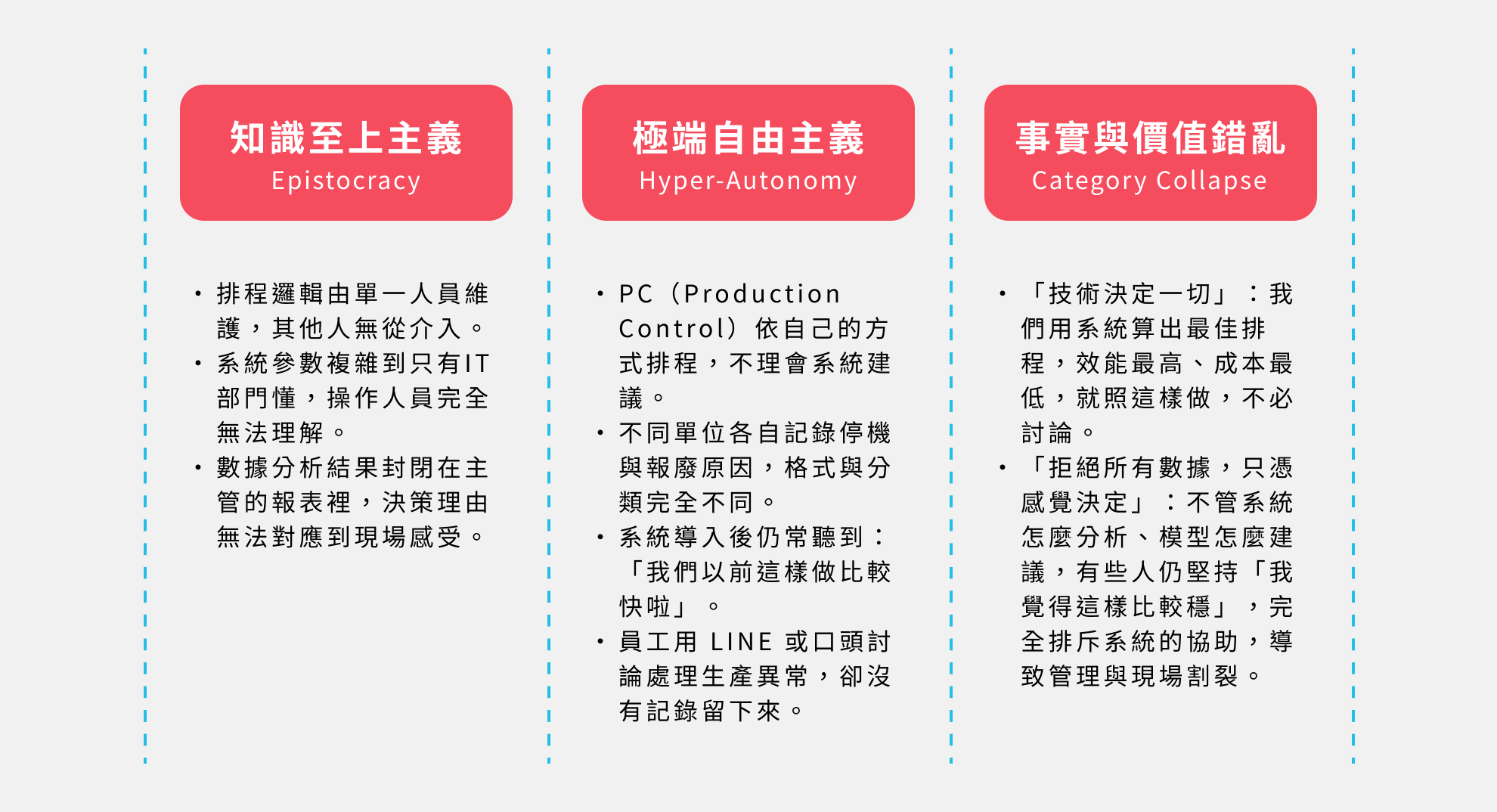
這三種錯誤模式,分別知識至上主義(Epistocracy)、極端自由主義(Hyper-Autonomy)和事實與價值錯亂(Category Collapse),這些錯誤模式不但真實存在,而且往往在數位轉型初期特別容易浮現,通常發生原因並非單純來自系統操作不當或人為疏失,而是出現在整體決策架構與文化中。當失衡嚴重時,會直接影響到企業落實數據驅動及 AI 決策的核心價值。
-
知識至上主義(Epistocracy)
在公司裡,管理階級經常會依賴著一些掛著「專家」頭銜的人做決策,但真的比較好嗎?「由他們做決策」聽起來好像很合理,畢竟經驗豐富、擁有資料與工具的人,理當掌握更多資訊。但問題出在這種「只允許少數人參與」的架構,會逐漸排除多數人的理解與參與。
許多製造業場域都有可能會遇到這樣的情況:
- 排程邏輯由單一人員維護,其他人無從介入。
- 系統參數複雜到只有IT部門懂,操作人員完全無法理解。
- 數據分析結果封閉在主管的報表裡,決策理由無法對應到現場感受。
信任斷裂、現場抗拒、甚至產生「AI 是來管我的」的錯誤印象。原本設計來輔助決策的工具,反而成了權力集中與資訊壟斷的決策黑箱。
為了解決這種「專家黑箱」,鼎華的 APS 導入AI Agent 設計重點之一,就是讓決策透明化、語意化、協作化。具體做法包含:
- 語意查詢介面:不需懂 SQL 或程式語法,只要輸入自然語言問題(如「這週哪條產線報廢率最高?」),AI 即可自動生成圖表與趨勢。
- 可視化決策邏輯:每個排程建議都可點選看「為什麼這樣排」、依據了哪些目標與限制條件,讓使用者不只是接收,而是理解。
- 多角色權限與協作介面:開放工程、品管、生產、業務等不同部門依自身角度參與調整,建立決策共識,而非少數人壟斷。
我們都理解知識固然重要,但當知識變成權力的壟斷,那麼即使是正確的決策,也可能被質疑、被抵抗、甚至被無視。
- 排程邏輯由單一人員維護,其他人無從介入。
-
極端自由主義(Hyper-Autonomy)
當每個人都說他有答案的時候,經常會出現沒有共識的狀況,因為當決策過程過度去中心化,每個人都依自己的想法行動時,結果不是更靈活,而是更混亂。
這種模式常見於反動於知識至上主義的文化下,員工開始質疑專家、排斥制度,強調「我自己最知道情況」,甚至認為「系統只是參考,我相信我自己的經驗比較準」。看似自主,實則決策失控、效率低落、資訊分裂。
在隱性經驗吃重的製造業中,這種情況經常可以見到:
- PC(Production Control)依自己的方式排程,不理會系統建議。
- 不同單位各自記錄停機與報廢原因,格式與分類完全不同。
- 系統導入後仍常聽到:「我們以前這樣做比較快啦」。
- 員工用 LINE 或口頭討論處理生產異常,卻沒有記錄留下來。
確實!這些做法或許短期看來能快速解決問題,但長期下來會導致什麼後果? 資料無法統整、判斷依據失準、決策過程無跡可循,更別提讓 AI 提供有意義的建議——因為 AI 根本「不知道大家是根據什麼在做決定」。
面對這樣的挑戰,鼎華在設計 APS 導入 AI 功能 時,特別重視三個方向:
- 資料結構統一與標準化:不論是停機紀錄、換線理由還是派工決策,每一筆都導入標準分類,讓資料具備整合基礎,避免「各自表述」。
- 知識模型與語意引擎:透過行業語義建模與知識圖譜,我們幫助 AI 理解現場語言,將「經驗」轉化為「可共享的規則與案例」。
- 自然語言查詢與決策協同介面:讓不同角色可以用自己的語言提問、參與、回饋,建構出橫跨部門的共識與行動依據。
我們相信,自主不是壞事,但前提是「有共識的自主」,並在明確規則中被授權的選擇,若沒有共享的邏輯與資料基礎,自主只會讓每個人越走越遠,AI 也將無從協助你找回方向。
- PC(Production Control)依自己的方式排程,不理會系統建議。
事實與價值錯亂(Category Collapse)
當科學被誤用,決策會走向極端
許多組織在「數據驅動決策」時最容易忽略的陷阱:事實與價值錯亂(Category Collapse)。也就是——搞不清楚什麼是事實、什麼是價值,結果不是讓科學承擔了道德判斷,就是用價值信念否定所有數據分析。
這種錯亂的兩個極端,在工廠裡都可能發生:
- 一種是「技術決定一切」:我們用系統算出最佳排程,效能最高、成本最低,就照這樣做,不必討論。這種邏輯忽略了價值層面,例如員工過勞、班表無法配合、品質風險增加等問題。
- 另一種則是「拒絕所有數據,只憑感覺決定」:不管系統怎麼分析、模型怎麼建議,有些人仍堅持「我覺得這樣比較穩」,完全排斥系統的協助,導致管理與現場割裂。
這樣的決策模式常見於導入 AI 的初期階段,原因很簡單——大家都把科學當作答案,卻沒意識到:科學提供的是依據,不是價值本身。
鼎華在系統設計中,深知這類混淆的風險。因此我們在 APS+AI 的應用邏輯裡,刻意設計出「事實與價值分離的使用機制」,包括:
- 事實層:資料判斷與建議建構
系統根據訂單、資源、產能與歷史紀錄,自動生成最適排程與預測風險。 - 價值層:使用者調整與選擇
使用者可以依據不同經營價值(如永續目標、加班政策、客戶等級)設定優先權與限制條件,讓 AI 的建議在「符合價值前提」下運作。 - 可比對的多版本排程模擬
我們允許多組條件同時運算,提供 A、B、C 三種排程版本,讓管理者理解不同價值選擇對決策的實際影響。
這樣的設計目的不是讓 AI 決定一切,而是讓管理者能清楚區分「這是資料說的」和「這是我選擇的」。
我們的理解是,錯的從來不是科學本身,而是我們沒有搞清楚:在做決策時,科學該扮演什麼角色,又不該越界到哪裡。當我們把技術分析當作價值判斷,或反過來用信念否定所有資料依據時,真正失衡的,不是系統、不是演算法,而是我們對科學與選擇之間界線的混淆。

這三種錯誤模式,讓我們更理解為何導入 AI 與智慧系統的過程,不只是技術升級,更是組織思維的重新校準。
三. 沒有結構化資料,就沒有可預測的運營
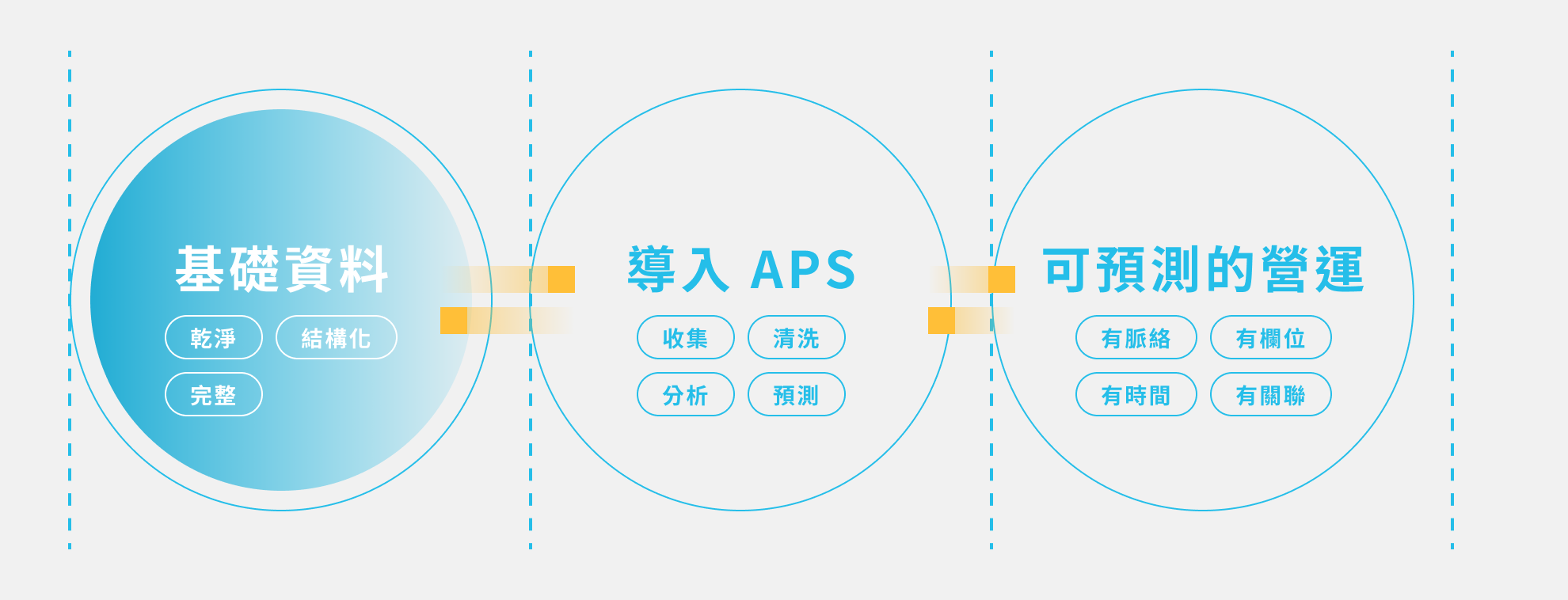
前面我們談了決策三角(The Decision Triangle)和三種錯誤決策模式,它們看似源自認知與文化,其實最終都會回到一個更根本的問題——資料能不能支撐決策?
這也是我們在導入:不論你導入多進階的 AI,沒有乾淨、完整、結構化的資料作為基礎,一切都只是推論的泡影。
鼎華的顧問在調研工廠現場時,也發現許多宣稱「我們已經數位化了」的企業經常會發生的狀況:
- 設備資料來自不同品牌,每秒更新一次的與每小時更新一次的混在一起
- 停機、報廢紀錄仍然靠紙本抄寫、下班後輸入,時間誤差高達數小時
- 良率統計雖有紀錄,但沒有標註對應工單、原料批號、操作人員,導致異常原因無從追溯
- 最致命的是各系統(MES、ERP、QMS)彼此未打通,資訊處於「孤島狀態」
這樣的資料,不僅無法餵給 AI 建模,連人都難以用來做出即時、可信的決策。
這就是為什麼我們在導入 APS 系統前,總是會先安排售前進行調研,並問客戶:「你們的資料,能被分析嗎?」鼎華一直強調,智慧製造不是從 AI 開始,而是從資料開始。具備結構化資料,代表每一筆訊息都有脈絡、有欄位、有時間、有關聯性——這是預測能力的根本。
舉例來說:
- 若機台停機紀錄能即時與生產單位、工單號碼、報廢紀錄連結,系統就能真正判斷出異常源頭
- 若換線記錄能與產品編號、加工順序、班次與稼動率一併分析,系統就能主動提供減少換線的排程策略
- 若品質異常能標註原料批號與供應商,企業就能快速進行回溯與預防
當資料先被收好、收對、收準了,就會形成結構化資料,就具備可信性和可預測。
四. APS 是 AI 決策的起跑線,更是智慧運營的核心基礎
當我們在談「AI 幫助決策」時,其實說的是一個流程,而不是單點技術。這個流程從資料收集、清洗、分析、預測,一直到形成有價值的行動建議,每一個環節都必須穩固銜接。若要讓這條路線順暢啟動,那麼第一步,就必須由 APS(Advanced Planning and Scheduling)系統來建立清晰可運算的運營模型。
我們經常說,APS 是智慧工廠的「排程中樞」──但更精準地說,它是 連接資料與決策的引擎。因為只有它,能將散落在 ERP、MES、QMS 等系統中的資料,轉化成「可被推論、可被選擇」的行動建議。
這些建議不是從空中生成的,而是基於企業真實的運營限制與策略邏輯,例如:
- 訂單交期 vs. 資源限制
- 生產成本 vs. 設備稼動率
- 班次人力 vs. 客戶等級
- 製程順序 vs. 換線次數
鼎華的 APS 系統,除了具備動態排程演算法、模擬優化能力,還設計了「排程條件組合 + 多版本模擬」機制,讓管理者可以根據不同場景需求,快速切換策略配置(例如:應對急單、原料短缺、或設備維修等情境)。
更重要的是,APS 不是獨立運作的單一系統,而是 MOM(Manufacturing Operations Management)架構中的核心節點──它承接 MES 的即時資料,也將排程輸出回到現場執行,形成決策的正向回饋。
當我們透過 AI 協助做決策,其實說的不是 AI 自己下判斷,而是 它能否站在一個正確、乾淨、邏輯清楚的資料起跑線上運作。而這條起跑線,就是 APS 所提供的決策環境。
如果沒有 APS,AI 再聰明,也只能看資料、做描述;有了 APS,AI 才能參與判斷、協助選擇,真正進入決策。
五. 我們如何協助工廠強化數據可靠性
從書本的理論,到工廠現場的落地,中間最大的挑戰,就是讓資料變得可信、決策變得可執行,而關於這一點,鼎華過去協助製造業數位轉型的過程中,有極深的體會。
我們服務過的許多企業,導入系統之初,往往都有一定的資料基礎,但實際運作時卻發現:
- 資料雖多,卻無法整合成結構邏輯
- 每個部門都有資料,但彼此格式與分類完全不同
- 系統之間資訊未串接,導致同一件事出現在三份報表上,卻說法不一
這不只是「資料品質問題」,而是整體資訊治理結構尚未準備好迎接 AI 決策的環境。
因此,鼎華的做法從來不是「直接導 AI 模型」,而是從源頭開始重建可靠性。以下是我們的三步驟策略:
1. 建立資料標準與語意結構
從工單編碼到製程分類,建立具備上下文的主資料架構,讓數據可以「彼此對話」,也讓系統能夠理解企業運營語境。
2. 串接即時訊號與系統資料
透過 MES、IoT 感測器與生產履歷系統整合,將機台稼動、停機異常、報廢原因、品質檢驗等資訊即時轉換為可運算的格式,餵入 APS 進行分析與推理。
3. 啟動語意查詢與多角色決策模擬
導入 AI Agent 與自然語言查詢功能,讓不同部門的人都能「用自己的語言問系統」,並透過多版本模擬排程,形成跨部門可討論、可驗證的決策基礎。
舉例來說,我們曾協助一家金屬加工廠,從過去報廢紀錄只寫「NG」三個字,轉化為標準化分類(如:進料尺寸誤差、刀具異常、夾治具滑移等),並將這些資料與排程、設備參數串接,讓 AI 不只看到異常,還能判斷出「異常發生在哪一段製程邏輯中」,並提出具體改善建議。
六. 總結|當我們談決策,我們其實在談:信任、價值和參與
回到這次閱讀《Third Millennium Thinking》的初衷,我們其實不是在找一個新概念,而是試圖重新理解,當我們談決策時,我們其實在談信任、價值和參與,換言之,我們每天在工廠裡、會議室中、系統背後做出的決策,究竟是建立在什麼之上?
書中提出的「決策三角」——資訊來源的可靠性、價值觀的正當納入、決策權的正當性——不只是學術模型,更像是一面鏡子,照出我們在追求智慧製造與 AI 輔助決策過程中,經常忽略的根本問題。
我們常問:「AI 會不會取代人?」
但真正該問的是:「我們給 AI 的資料,能不能信任?我們在做決策時,有沒有納入不同價值?我們的流程,是否讓人能理解並參與?」
這三個問題,正對應著《Third Millennium Thinking 三禧思維》所揭示的三大要素:
- 資訊可靠性,解決「我能相信什麼」
- 價值納入,回答「什麼對我來說重要」
- 程序正當性,建立「這是我也參與的選擇」
鼎華相信,智慧製造不只是技術升級,更是一種讓資料更透明、讓決策更有邏輯、讓人更願意參與的文化轉變。APS、MES、QMS 這些系統不是目標,而是過程中必備的工具。AI Agent 也不是接管人類,而是協助我們在複雜環境中做出更有品質的判斷。
若要在這個數位轉型浪潮中站穩腳步,我們不只要快,更要準;不只要自動化,更要「思考的自覺」。
這篇文章不是結論,而是我們閱讀後的一次整理與對話邀請。如果你也正在思考如何提升決策品質、讓 AI 發揮真正價值,我們很樂意繼續分享,甚至一起設計屬於你工廠的智慧決策邏輯。
因為——真正能驅動未來的,不是工具,而是理解與選擇。
想讓 AI 成為你決策團隊的一員?從資料治理、流程可視化,到決策模擬與價值條件設定,鼎華提供的不只是技術,更是一套以「信任、價值、參與」為核心的智慧決策環境。
歡迎聯絡我們,一起打造讓 AI 真正發揮作用的決策基礎。

